This is a guest post by Hyro - a Mona customer.
What we learned at Hyro about our production GPT usage after using Mona, a free GPT monitoring platform.
At Hyro, we’re building the world’s best conversational AI platform that enables businesses to handle extremely high call volumes, provide end to end resolution without a human involved deal with staff shortages in the call center, and mine analytical insights from conversational data, all at the push of a button. We’re bringing automation to customer support at a scale that’s never been seen before, and that brings with it a truly unique set of challenges. We recently partnered with Mona, an AI monitoring company, and used their free GPT monitoring platform to better understand our integration of OpenAI’s GPT into our own services. Because Hyro operates in highly-regulated spaces, including the healthcare industry, it is essential for us that we ensure control, explainability, and compliance in all our product deployments. We can’t risk LLM hallucinations, privacy leaks, and other GPT failure modes that could compromise the integrity of our applications. Additionally, we needed a way to monitor token usage and the latency of the OpenAI service in order to keep costs down and deliver the best possible experience to our customers.
Mona aligns with our core values of transparency and security, so working with them was a natural fit. Furthermore, as long-term customers of Mona, we’ve seen the value in applying their existing monitoring solutions within our tooling, so we wanted to see how the GPT monitoring integration could further improve our results. What we gained was a significantly improved understanding of user behavior and how to reduce token usage, insights into unanticipated user scenarios, improved visibility into application performance and reliability, and ideas for how to improve prompt efficiency.
Understanding User Behavior and Token Usage
Mona’s GPT monitoring solution delivered immediate, bottom-line benefits through reductions in token usage, thereby lowering our backend costs. As a concrete example, Mona alerted us to a particular conversation within our product that was resulting significantly higher than normal token usage. This is something that Mona’s platform excels at – identifying anomalous segments in data. A bit of digging into this scenario alerted us to a situation that we hadn’t foreseen: one of our users was answering our English-speaking chatbot in Spanish. This resulted in mixed-language prompts being sent to the OpenAI backend, which in turn provided far from ideal results and was hurting the user experience. The unforeseen mixed-language prompts caused our chatbot to repeatedly ask the users the same questions and resulted in significantly increased token usage. We decided this scenario would be better addressed preemptively, and we devised a method to identify these foreign language uses prior to sending prompts to the GPT API and respond to the user that we cannot handle Spanish. We also are working multi-language skills where there is high demand for Spanish. All of this allows enhanced user experience while cutting down on our costs.
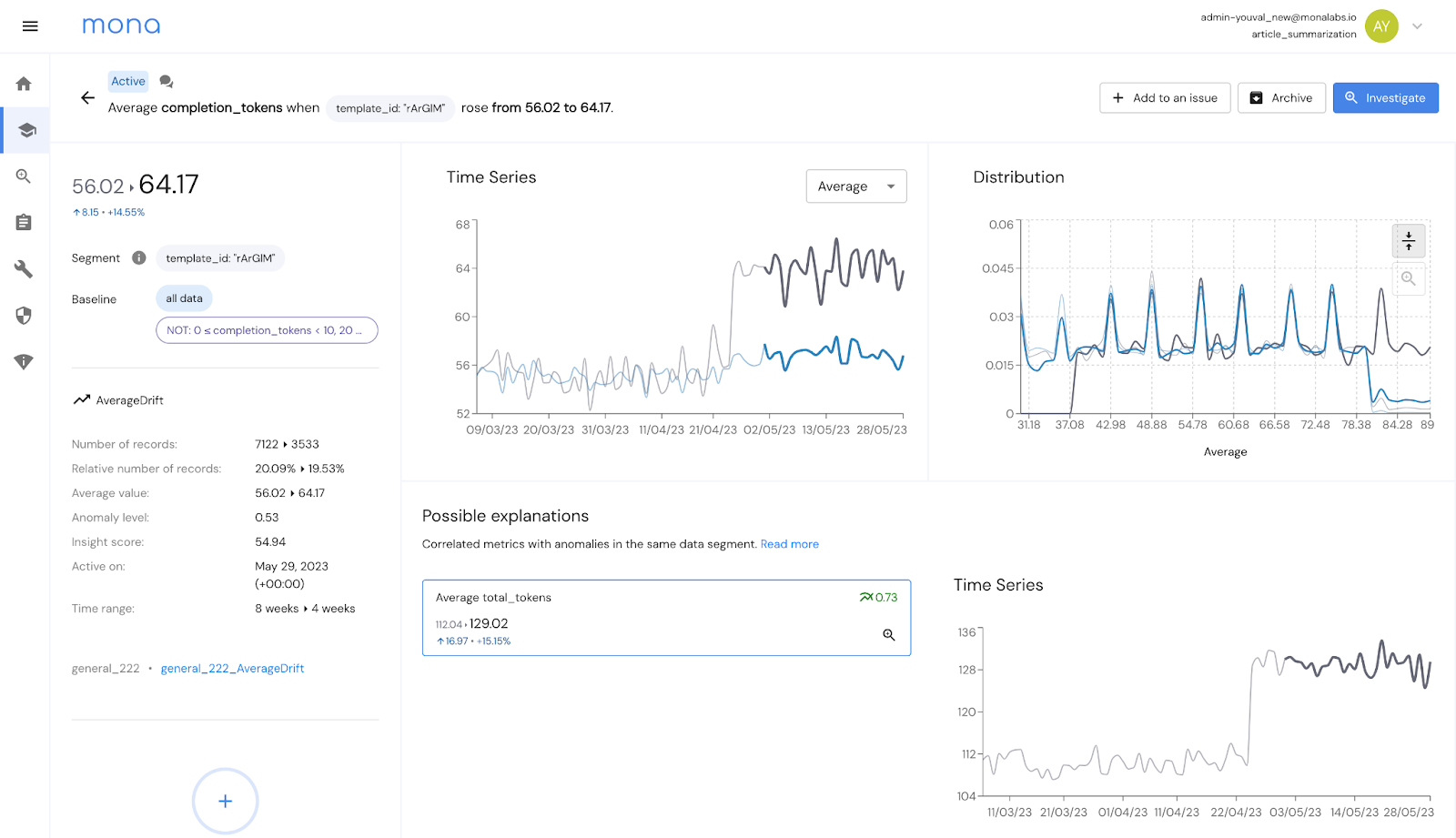
A Mona “Insight”, alerting on an increase in average token usage for a specific prompt template
Visibility into Application Performance
Because our platform handles customer interactions in real-time, application performance is of the essence. Guaranteeing uptime and reliability can be difficult when integrating with third-party services such as the OpenAI API, which is prone to sporadic instances of high latency and can introduce its own set of exceptions. The Mona GPT monitoring integration enables visibility into all of the relevant metrics by tracking parameters such as latency and exceptions rates / reasons. It also alerts us to the specific places where these metrics misbehave, be they the geographic location of a data center on which our application is running or the specific prompt templates that are causing exceptions to arise. When provided with these alerts, we’re able to take immediate, remediative action, be that alerting on-call engineers, short-circuiting the use of GPT, or raising flags to Azure, our cloud computing and GPT provider. Regardless of the specific remedy, having the mechanisms in place to be automatically alerted to problematic behavior is crucial when hosting an application of this size and scale.

Mona’s dashboard provides visibility into GPT usage
Discovering New Prompt Efficiencies
As many know, GPT is sensitive to the way in which it’s prompted. Designing the best possible prompt takes trial and error, but it can often be difficult to evaluate different prompts and compare their performance. Mona’s GPT integration has enabled us to identify prompting patterns for which token usage is unexpectedly high. On one specific occasion, Mona alerted us to an anomaly in token usage that we were unaware of. Upon further investigation, we found that one prompt template incorporated a user-provided list of unbounded length which could incur extremely high token usage costs. We were able to take action on this by implementing a pre-processing algorithm which shortened and capped the length of that list, enabling us to cheaply and quickly limit our downside on token costs.
Conclusion
We’ve only been working with Mona’s GPT monitoring integration for a few weeks, and we are still discovering ways in which it can improve the robustness and reduce the costs of our GPT-based products. Even when we’re not directly taking action on Mona-generated alerts, having their monitoring integration running gives us the confidence and peace-of-mind that nothing untoward is happening in our use of third-party APIs and services. GPT is a powerful force multiplier for us as a business operating in the conversational domain, but we still need to limit the risks of using what is, in many ways, still an untested and experimental service. The reassurance that Mona gives us in incorporating these services into our own products has been nothing short of a game changer.