AI systems are no longer confined to research labs—they’re deeply embedded in high-stakes, real-world business processes across industries. Whether powering fraud detection in finance, personalization in e-commerce, or decision-making in healthcare, machine learning models are now mission-critical assets. But with great impact comes great risk.
This is where AI monitoring becomes essential. Without a robust monitoring framework, even the most accurate models can silently fail—drifting from their original intent, degrading in performance, or causing unintended downstream consequences. In production, the cost of unnoticed model failures can be immense: customer churn, regulatory penalties, reputational damage, and lost revenue.
In this definitive guide, we’ll walk you through everything you need to know about AI and ML monitoring: why it's critical, how to get started, what challenges to expect, and how to choose the right tools. Our goal is to equip you with a modern, product-oriented approach to monitoring that aligns machine learning with real business value—making AI systems more transparent, accountable, and resilient.
Whether you're a data scientist, MLOps engineer, or business leader, this guide will help you understand how to put AI monitoring at the heart of your AI strategy.
Table of contents
Machine Learning Monitoring Overview
Machine learning monitoring is a critical component of managing ML models in production. It enables teams to gain visibility into model performance and ensures models continue to operate as intended. Beyond technical oversight, monitoring is essential for deriving real business value from AI systems.
Without a clear understanding of how model predictions impact key business metrics—such as KPIs and revenue—it's impossible to confidently improve or optimize your ML pipeline. Effective monitoring allows for early detection and resolution of issues before they escalate into major system-wide failures.
Consider this example:
A bank deploys a fraud detection model into production, applying it to every customer transaction. Initially, business leaders celebrate a noticeable drop in reported fraudulent activity. However, without robust monitoring tools, a critical issue goes unnoticed—the model is generating a high volume of false positives.
These false alerts result in loyal customers being mistakenly locked out of their accounts or having legitimate transactions declined. Frustrated by the experience and the burden of resolving it through customer support, many of these customers quietly leave for competing banks.
This churn remains invisible until the financial impact surfaces in a quarterly earnings report—by which time the damage is already significant. Rebuilding trust and stopping further customer loss becomes a slow and costly recovery effort—one that could have been avoided with proper machine learning monitoring in place.
Why Do You Need ML Model Monitoring?
The previous example highlights a critical truth: without proactive oversight, small modeling flaws can snowball into significant business problems. ML model monitoring is designed to prevent this by offering real-time visibility into model behavior in production—allowing teams to detect and resolve issues before they impact customers or the bottom line.
This approach stands in stark contrast to the reactive strategies still common in many organizations, where dashboards and investigations are only triggered after customer complaints arise. While such methods may uncover some issues, they often come too late—after the damage is done and business metrics have already suffered.
Proactive monitoring enables early intervention, helping organizations stay ahead of potential problems. It's a foundational capability for any business that wants to not just survive, but thrive, in an AI-driven environment. Rather than reacting to failures, monitoring empowers teams to continuously improve, ensuring AI systems contribute to sustained growth and customer trust.
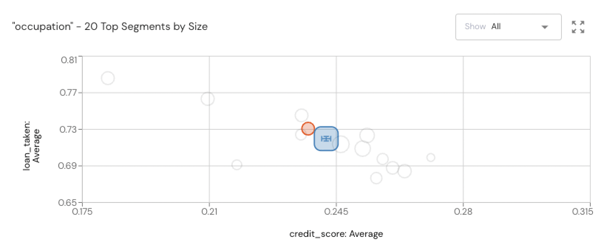
Monitoring provides complete visibility into AI-driven applications, from the initial point of data ingestion to the issuance of a prediction, to the endpoint of an affected business KPI. This allows data scientists and engineers to identify critical issues such as data and concept drift, problems that can’t be solved through simple methods such as model retraining alone.
Furthermore, ML model monitoring yields granular insights that can be used to optimize model performance and enable organizations to take a product-oriented, rather than research-oriented, approach to their modeling workflow.
Getting Started with AI Monitoring
Getting started with AI monitoring is more straightforward than it might seem. The first and most important step is to define performance metrics that reflect the business value your ML model is meant to deliver. These metrics should be:
-
Business-aligned: Directly tied to the outcomes your organization cares about.
-
Segmented: Tracked across different slices of the data to catch localized issues.
-
Interpretable: Simple to understand and compute, yet representative of meaningful model behavior.
For example, in an ad recommendation system, a useful metric might compare the model’s confidence level in serving an ad with downstream outcomes—such as whether the user ignored it, clicked, converted, or even the size of the conversion.
In contrast, a fraud detection model might rely on a simpler metric, like mean squared error, to measure how far the model’s fraud confidence score deviated from the true outcome.
Monitor Both Features and Outputs
Effective AI monitoring goes beyond just watching model outputs—it also requires keeping a close eye on feature behavior. Features are the inputs that drive predictions, and changes in their distribution over time (data or concept drift) can silently degrade model performance.
Monitoring feature drift helps explain why a model may start behaving unexpectedly. Tools like SHAP and LIME are widely used to interpret model outputs by showing how input features contribute to specific predictions.
Additionally, capturing user metadata can greatly improve your ability to segment and diagnose issues when anomalous metrics arise. For instance, if drift is detected, metadata can help pinpoint which user groups are affected and whether retraining is necessary.
The Golden Rule: Track Everything
The most important principle in AI monitoring is simple: track everything. Every stage of the ML pipeline—from data ingestion to preprocessing, training, testing, and inference—should be monitored. This full visibility allows teams to:
-
Debug issues more efficiently
-
Trace anomalies to their root cause
-
Respond to shifts in data or performance before they harm business outcomes
In short, comprehensive monitoring builds confidence in your ML systems and ensures that your models continue to perform reliably, even as real-world conditions evolve.
How to Track ML Model Performance
Monitoring ML model performance is critical to ensuring long-term model reliability and business impact. The best monitoring systems offer automatic anomaly detection at a high level of granularity—essential for identifying the subtle issues that can destabilize even high-performing models.
The Importance of Granular Monitoring
Machine learning models are often highly sensitive to small changes in their inputs. Seemingly minor distributional shifts can lead to unexpected predictions or degraded performance. These shifts typically fall into two categories:
-
Data Drift – When the input data distribution changes over time.
-
Concept Drift – When the relationship between inputs and target outputs evolves.
Monitoring for drift starts by examining small, well-defined data segments, as early shifts often appear in narrow slices before affecting the broader dataset. This early detection helps prevent large-scale model failures.
Aligning Model Metrics with Business KPIs
To ensure that model improvements translate into tangible business value, it's vital to define metrics that correlate model performance with business outcomes. For example, accuracy or precision might matter for a fraud detection model, while click-through rates or conversion value might be more appropriate for an ad recommender. Choosing the right metrics ensures that optimizing model performance drives the desired business results.
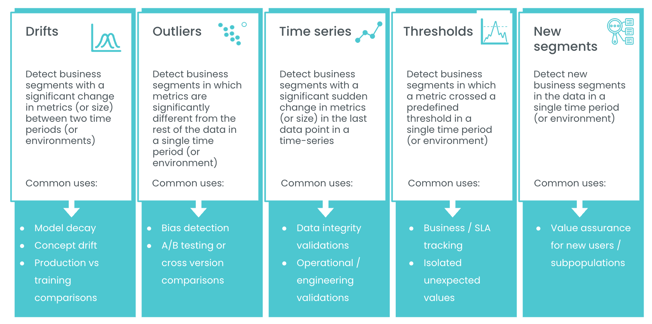
Common Anomalies to Track
A robust monitoring system should be equipped to detect various types of anomalies, including:
-
Outliers – Extreme values that can distort key metrics like averages and lead to misleading insights.
-
Threshold Violations – When model metrics (e.g., precision, latency, or error rate) exceed or fall below set thresholds.
-
Time-Series Anomalies – Fluctuations or noise in time-based data that can lead to overfitting or misinterpretation.
-
Model Decay – A gradual decline in model performance after deployment, often due to undetected drift.
-
Hidden Biases – Subtle and difficult-to-detect patterns that can result in unfair or unethical predictions.
📊 Note: Visualizing these anomalies—through dashboards or alerts—can greatly improve response time and help prioritize retraining or remediation efforts.
The Need for a Comprehensive Monitoring Toolkit
Given the diversity of ML models and the variety of data they handle, it’s essential to use a monitoring solution that offers:
-
A wide range of anomaly detection methods
-
Support for different data types (structured, unstructured, time series, etc.)
-
Flexibility to define custom metrics and thresholds
-
Integration with your existing ML infrastructure
Comprehensive monitoring ensures end-to-end visibility across your ML pipeline, empowering your team to proactively manage and improve model performance under real-world conditions.
Largest Challenges in AI Monitoring and How to Overcome Them
1. Escaping the Research Mindset
One of the most significant obstacles organizations face when implementing AI solutions is remaining stuck in a research-centric mindset. Given AI’s roots in academia and its ongoing evolution through research labs, this is understandable—but problematic.
In a business setting, AI must be treated as a product, not just a proof of concept. This means integrating models directly into workflows, continuously evaluating their real-world performance, and measuring impact through concrete business metrics like KPIs. Without this shift in perspective, AI initiatives risk stalling at the prototype stage, failing to generate real value.
Solution:
Adopt a product-oriented approach. Embed AI models as integral components of operational processes and measure their success through business outcomes. Establish feedback loops—whether direct (e.g., user interactions) or proxy (e.g., human evaluations, confidence scores)—to enable ongoing refinement and performance tracking.
2. Feedback Fragmentation and Siloed Systems
Another major challenge in AI monitoring is gathering the right feedback, especially when it’s distributed across different systems, platforms, or teams.
For example, if you’ve built an ML-powered chatbot for customer support, you need interaction logs to evaluate how well it handles queries, redirects requests, or resolves issues. However, in many real-world organizations, such data is scattered, inconsistently stored, or inaccessible to those responsible for model performance.
Solution:
-
Break down data silos by improving cross-team collaboration and system integration.
-
Revamp infrastructure to ensure critical logs and feedback data are systematically captured, centralized, and made available to the right stakeholders.
-
Promote data accessibility as a core part of your AI strategy, not an afterthought.
3. Lack of Version Control and Testing Infrastructure
AI systems are dynamic. Models evolve, training data changes, and even seemingly minor updates can introduce regressions. Yet many organizations lack the tooling to track these changes properly.
Solution:
Implement robust version control for both models and datasets, just like in software engineering. This enables:
-
Easy rollbacks in case of performance degradation
-
Clear diffs between versions to track what changed and why
-
Seamless A/B testing, allowing you to evaluate different models or configurations on live traffic to identify the most effective solution
When combined with monitoring, versioning and testing create a resilient ML workflow that supports fast iteration without sacrificing stability.

4. Balancing Granularity and Noise in Monitoring
As emphasized throughout this guide, effective monitoring depends on analyzing performance at a granular level. But zooming in too far introduces a new problem: noise. Random variance can be mistaken for meaningful patterns, leading to false alarms or wasted effort.
Solution:
Use monitoring tools designed to intelligently surface anomalies. The best systems apply statistical techniques to differentiate signal from noise, helping you detect:
-
Emerging data drift in specific user segments
-
Outlier behavior in model predictions
-
Meaningful shifts in business-impacting metrics
This enables teams to focus on real issues without being overwhelmed by insignificant fluctuations.
Evaluating AI Monitoring Solutions
Choosing the right AI monitoring solution can be overwhelming. With no universal checklist available, it’s easy to get lost in the sea of features and marketing claims. However, the most effective ML monitoring platforms consistently share a few key characteristics.
The ideal solution should:
-
Be business process-oriented, integrating seamlessly with your workflows
-
Allow you to define custom performance metrics aligned with your KPIs
-
Provide automatic, granular anomaly detection
-
Support feature and output tracking
-
Handle diverse data types—from time series to categorical and tabular data
Beyond these essentials, there are three must-have capabilities that every solution should offer (e.g., tracking classifier failure rates or similar diagnostic insights).
What to Avoid
Not all solutions are created equal. As you evaluate tools, be wary of the following pitfalls:
-
"Out-of-the-box" promises: Monitoring isn’t one-size-fits-all. Expect to configure your own metrics, integrate with your business systems, and fine-tune anomaly detection to match your model’s needs.
-
Over-reliance on cloud provider tools: While these often include basic features like input/output logging and drift detection, they typically lack the contextual insights needed for true end-to-end observability.
-
Fragmented tools: Avoid point solutions that handle only one part of the monitoring process—such as basic APM tools, standalone anomaly detectors, or limited experiment tracking software. These tools often leave gaps in coverage and can’t provide the unified visibility needed for effective AI operations.
Instead, look for comprehensive, fully-featured platforms that offer:
-
Full system observability
-
Granular, configurable insights
-
End-to-end support for the entire ML lifecycle
Build vs. Buy
Another key decision is whether to build your own monitoring platform or buy a commercial solution.
-
Building may be appropriate for companies with large, specialized teams and the time and resources to develop, test, and maintain a custom tool.
-
But for most organizations, buying is the more practical option. Commercial platforms have the benefit of being battle-tested, refined over years, and supported by expert teams—saving you time, cost, and complexity.

Final Thoughts
We hope this guide has provided clarity as you consider how to incorporate AI monitoring into your business processes. These insights come from our work with many organizations striving to establish effective monitoring strategies for their AI systems.
While there’s no universal solution, the best platforms empower you to:
-
Extract maximum value from your AI initiatives
-
Detect and address critical issues early
-
Deploy ML systems confidently and efficiently
With the right monitoring foundation in place, AI can evolve from an experimental tool into a reliable, value-driving asset for your organization.