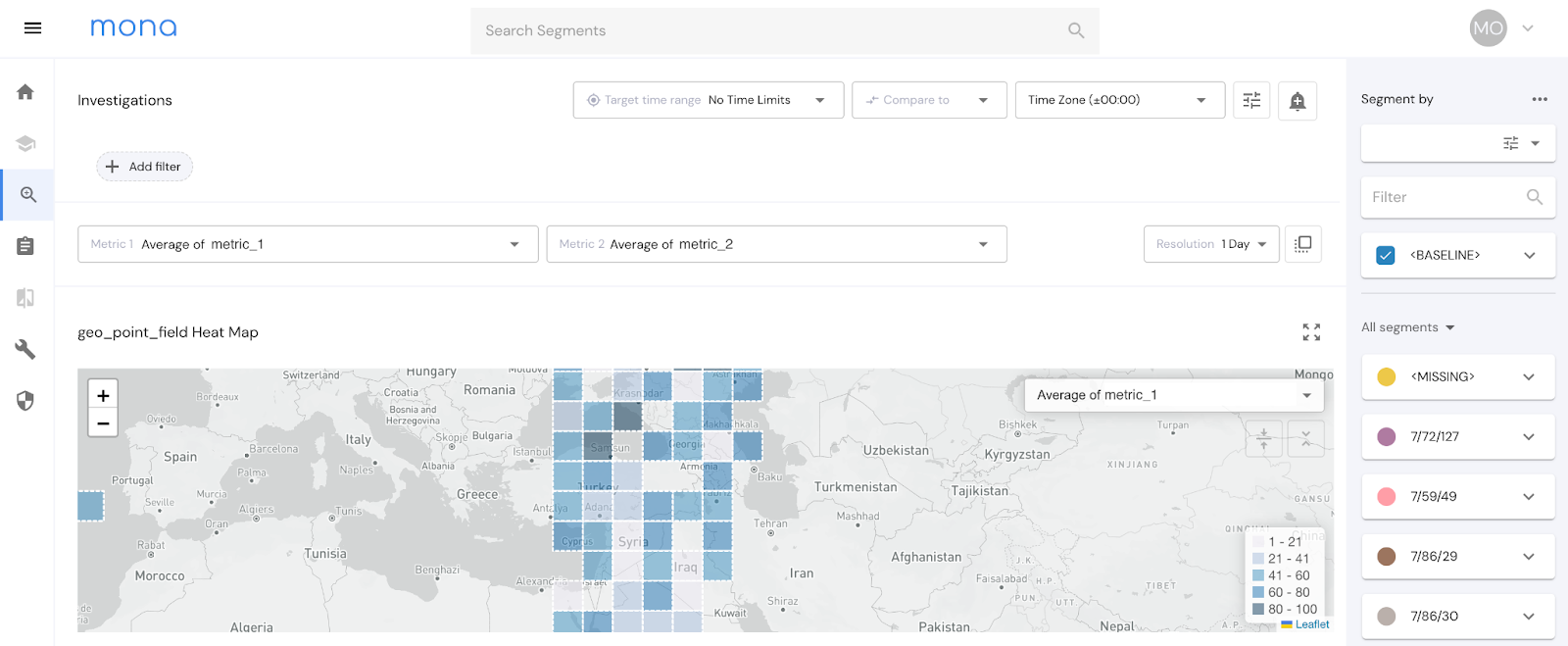
In today's data-driven world, organizations increasingly rely on data to inform their decision-making, resulting in the need for efficient and accurate data analysis tools. In the last two decades, a plethora of tools for analytics, data science, and BI have been created to meet this need. However, one basic problem in data analysis has remained elusive: the problem of automating multivariate exploratory analysis clearly and free of noise.
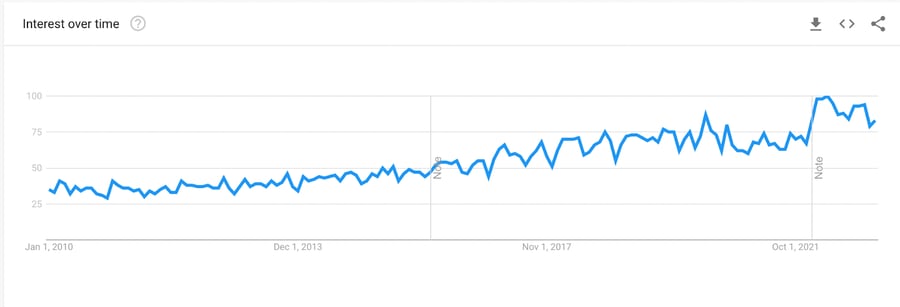
Google search trend for the term "dat driven" over the past 12 years.
Challenges of Multivariate Analysis
The problem lies in the fact that datasets often contain many dimensions in which identifying the meaningful patterns and anomalies is challenging to find. For example, a sales dataset may contain many dimensions such as geographical information, customer demographics, information about sales representatives, product information, the price it was sold at, and the margin on the sale. Upon analyzing this data, it is often required to determine the specific segments of the dataset where the metrics behave differently from the rest of the data. In this instance, it may be necessary to find the specific city in which the items are sold for a lower margin or even look within the last weeks to see if there is a specific brand that had a significant decrease in sales.

When sales in NY go down across all brands, one can mistakenly think there’s something wrong with Brand “X”, because most of its sales are in NY - when in fact in other cities brand X is doing just fine. This is the essence of multi-variate analysis.
However, it is not always easy to find such segments of the data since that will involve manual sifting through large amounts of data which can be time-consuming and prone to human error. Even if a segment is identified, determining its significance and whether it is truly the root cause of the anomaly can be challenging. Going back to the previous example, if there was a specific city and a specific brand of products in which sales have decreased, it could be that this brand is just sold mainly in that city. When checked in other cities, this brand is performing typically as it was before. To ensure accurate analysis, companies often employ large teams of BI and data analysts at a great expense. These teams spend a significant amount of time and resources going through the data in search of relevant insights.
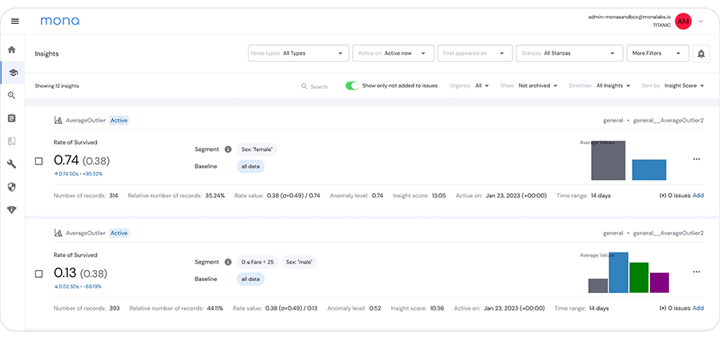
Mona’s automated exploratory data analysis tool provides insights into specific data segments that behave anomalously.
Eliminating Manual Data Sifting
Until now, there has not been an automated way to find the root-cause segment that drives the anomaly. We are excited to introduce a new tool that addresses this challenge head-on. Our tool is designed to take any tabular dataset and, with a simple configuration, automatically identify segments that exhibit anomalous behavior. Mona understands the real anomalous segments in the dataset and provides alerts on them, avoiding any noise. In the example that was discussed earlier, if other “symptoms” of the anomaly arise, Mona’s intelligent tool will determine that it is just a symptom and will not alert on mere symptoms. It then correlates these findings with other relevant metrics in the dataset to provide a comprehensive understanding of the underlying patterns, thus determining the cause of the original anomaly. This is crucial in avoiding false positives and ensuring that the insights generated are actionable and relevant.
Watch a recorded tutorial demo of Mona’s automated exploratory data analysis solution
Mona is the first to develop a solution that solves these tough challenges of analyzing multivariate datasets. With Mona, you can significantly reduce the time required to research datasets, do exploratory analysis, and generate valuable insights. It is completely free, easy-to-use, and works on any vertical. Simply upload a .csv file and let Mona do the heavy lifting. Sign up on our website to get instant access to Mona's automated exploratory data analysis tool!