As our customer base grows and the number of production AI use-cases being monitored by Mona increases, our team has been working tirelessly to advance our product to become a best in class AI observability solution.
Our product philosophy has always been to put the data scientist at the center and provide them with an intuitive yet robust engineering arm, with which they can easily monitor and extract valuable insights from their production AI systems. All in order to reduce operational risk and extend research capabilities into production.
As we began working with our earliest customers, we quickly realized that every AI use case is as unique as a snowflake. Every system has its own way of measuring behavior and performance. Therefore, we first set out to create the most flexible and analytically advanced monitoring capabilities. I am proud to say that Mona now serves customers in over 6 different business verticals, running on the various cloud and on-premise infrastructures and monitoring dozens of models of all types, from fraud detection and risk analysis to deep neural networks classifying audio, video, and image data.
Lately, we’ve been working hard on a milestone version of Mona which takes our capabilities to the next level, improving on usability, streamlining ML operational workflows, and advancing our analytical capabilities even further.
So without further ado, I’d like to present to you some of the main new features in our largest-to-date release.
New model version benchmarking and A/B testing
A great benefit of having granular visibility into how your ML models are behaving is that you can become much smarter about releasing new model versions (or any other versioned components, such as feature building pipelines).
Today, most teams use the average value of a specific loss function on a labeled test data set to decide if a new model version is better than the one currently in production. More advanced teams may apply shadow mode with some A/B testing on real production data to know if they can give a green light.
Mona takes such A/B testing and benchmarking capabilities to the next level. We now offer granular drift detection not only across the time dimension or between training and inference data, but also across model versions. Mona can automatically detect when data is flowing through a new model version and will alert you on specific underperforming segments in the new version when compared to older versions. This capability is supported both when the data comes from a batch run on a test set, or when the new version is already deployed in production, either in shadow mode or with real customer-facing outputs.
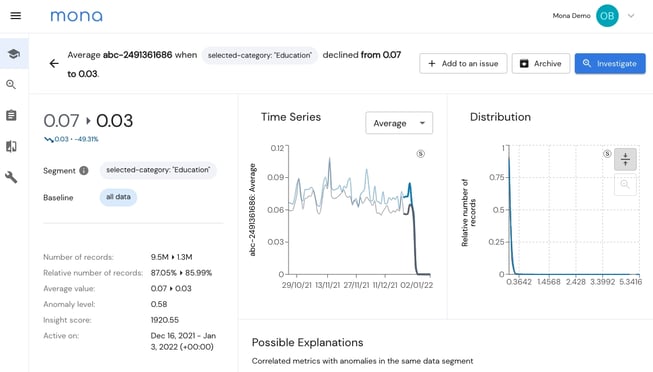
Mona found that the new model version is less confident about data coming from the UK when compared to older versions
See more in our documentation about this new verse type.
All of Mona’s capabilities, now easily accessible via an intuitive GUI
As I mentioned, one of our main initial challenges was creating a platform that is customizable enough to adhere to the intricacies of all AI use-cases and model types. We created an intuitive-yet-robust configuration language, built on top of simple JSON files. Today, we are launching a whole new user experience that allows our users to easily configure their monitoring use-case directly from their dashboard. Want to set up a drift detection alert on any feature within any customer or geography? This can now be done with a couple of clicks.
Monitoring with Mona is like poetry. Adding a “verse” to detect drifts in specific features for data coming from any company_id or country.
How about defining a new performance metric by using a predefined loss function between your model probability output and the actual business outcome? Just define a new field with one of our “field-building functions” directly on the dashboard, and Mona will automatically index this newly created data field with our internal ETL pipeline.
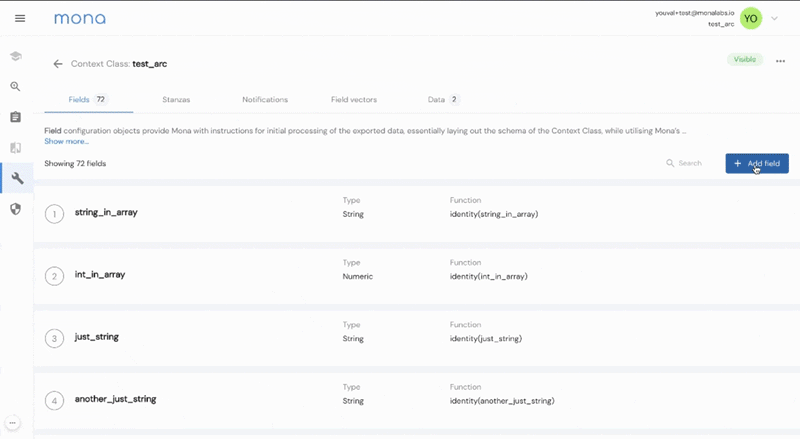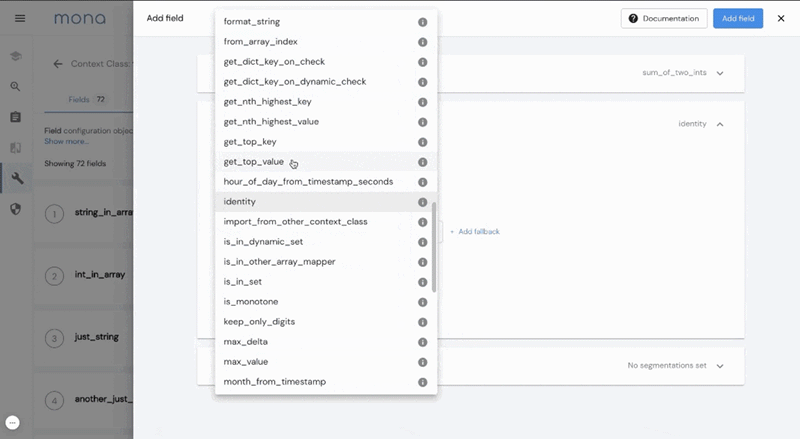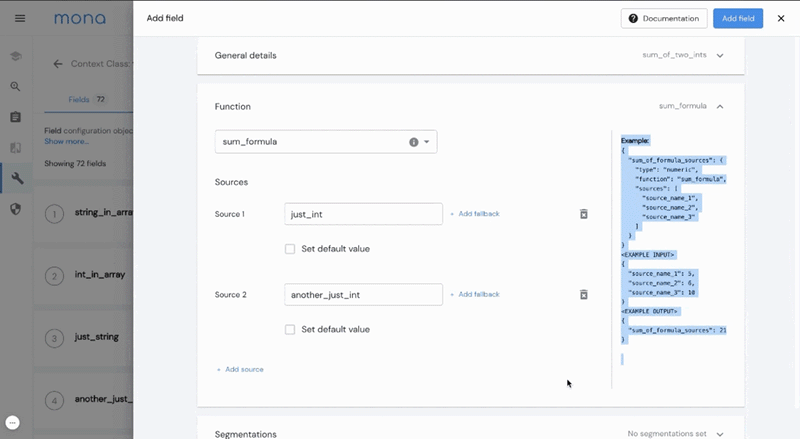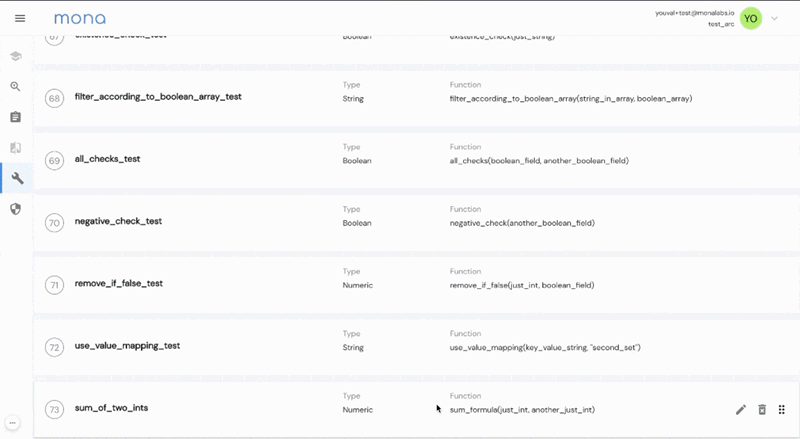
Mona’s configurable ETL takes care of defining and calculating any new data field from the data you already exported, separating your business logic from the monitoring logic.
Near real-time model monitoring
As part of this release we are also announcing a much-anticipated backend upgrade, which allows us to promise real-time alerting on sudden changes in metrics (features, outputs, or any other user-defined metric) distribution for a time granularity of up to 15 minutes, and with no more than 20 minutes latency. This is done while creating ad-hoc time-series models for thousands of data sub-segments, and while allowing a separate data ingestion channel for monitoring batch processes without interrupting the real-time monitoring.

Mona found a sudden change in the failure rate of a category classifier for data coming from a specific customer id
Mona has a notification management system that directs different alerts to different output channels/addresses and that integrates to slack/MS teams/pagerduty/email to alert you on such issues.
ML monitoring management
In monitoring the functionality of AI systems, not every issue has be dealt with in real-time. While some insights and alerts should be handled urgently on arrival (e.g., due to data integrity issues), many relevant insights are only actionable in the longer term.
For example, learning that an average prediction confidence interval is gradually drifting is relevant in order to set priorities, make sure to keep track of it (perhaps to see if it occurs in other use-cases as well), and to take actual action in the coming sprint.
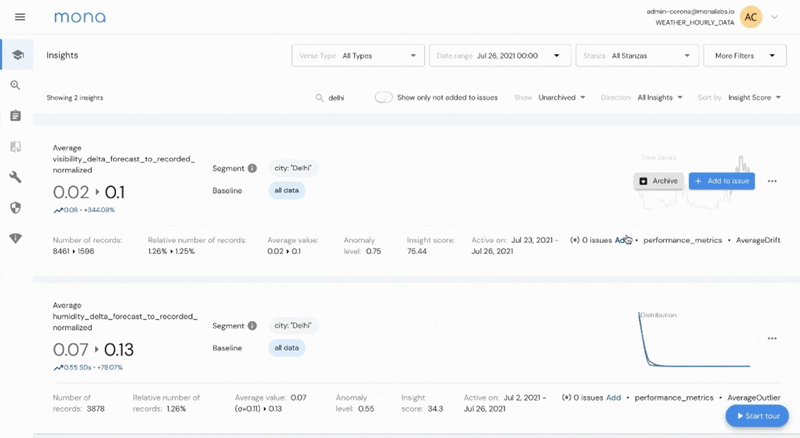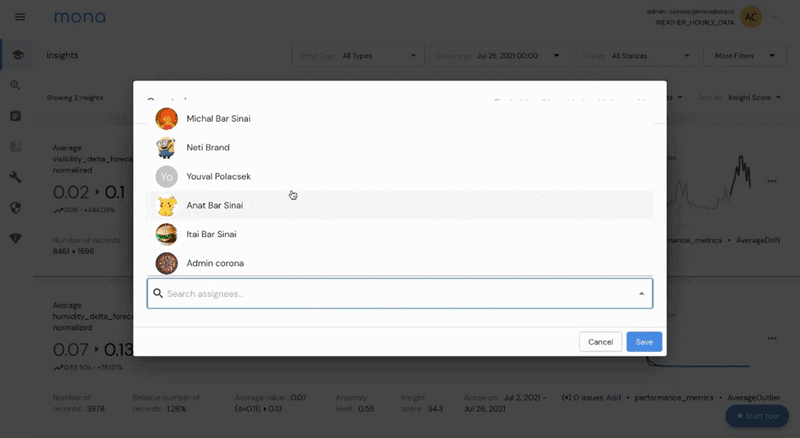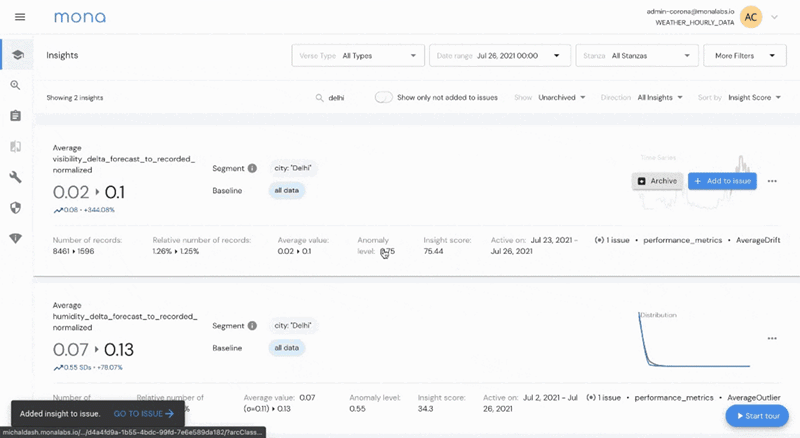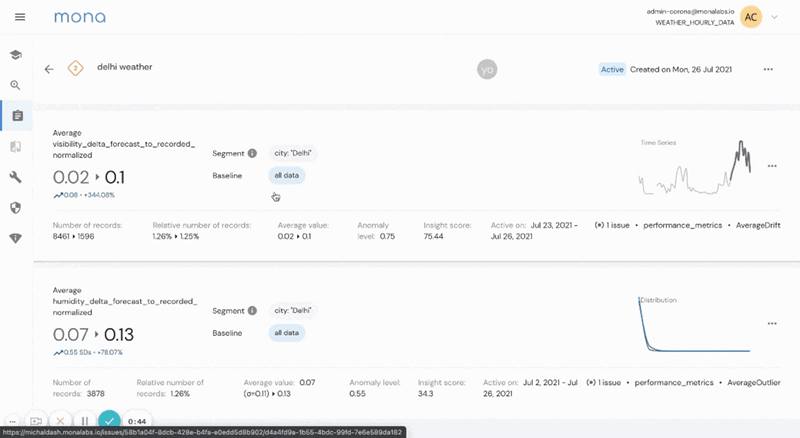
To make this kind of workflow straightforward, we are releasing a new thin issue-management layer, in which users can organize insights into “issues”, track them over time, assign them to relevant owners and discuss them all within the dashboard. Soon, you will be able to integrate these “issues” with commonly used task management tools such as Jira and Monday.
The main idea is to keep your “insights inbox” empty - once a new insight is found according to your specific configuration, directly assign it to a new or existing issue, or archive it if not relevant.
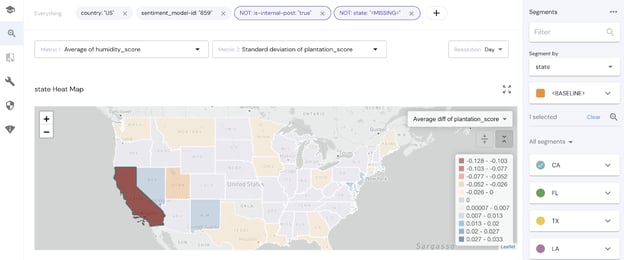
Geo-specific data? See your insights on a map!
In many AI use-cases, the physical location of an event is a very relevant piece of information. For example, a German language classifier might vary in its performance given different accents and dialects, which are usually a function of location within German-speaking countries.
To help our customers visualize and analyze their geo-specific data, we created a new map visualization along with a new field type for geodata.
Where do we go from here?
As we continue our journey to bring observability and trust for AI systems, time after time we’re amazed at the scale of this challenge. As major regulations regarding our use of AI start to show up, and as AI is becoming a ubiquitous business driver across most business verticals, making sure you have eyes and ears in the right places is a must to assure your business realizes the value of this AI investment while minimizing risk. We will continue to advance our platform to address all observability needs of data teams and AI systems.
Please join our newsletter to keep up to date with our product advancements, as well as interesting content from the industry. If you're interested in learning about how a flexible AI monitoring solution can significantly reduce any risks to your business KPIs, sign up for a free trial or schedule a demo.