Below, we use the term AI system. By this, we mean any software system that incorporates at least one predictive model, leveraging machine learning, statistical modeling, or any other AI techniques. A few examples: An automatic fraud detection system, a recommendation system, an image classification system, and a sentiment analysis of social media posts.
ML observability: A foundational need of AI systems
With AI rapidly expanding to critical business use cases across verticals, the “pressure is on” for data teams. These teams are accountable for producing and maintaining high-quality predictive models and to continuously improve these models.
Being accountable, data scientists and data engineers are “losing sleep”. Everywhere we go, we hear concerns about a variety of issues which are inherent to AI systems. What worked well in the research stage may not work well in production, and good performance “today” does not guarantee good performance over time.
Why?
By design, predictive models have biases. Machine learning model biases sometimes lead to underperformance for a sub-segment of the data. Sometimes these biases are driven by the training data being weighted differently from the data flowing in production. Biases could go undetected for some time if performance is not monitored at a granular level.
Also — by design, AI systems are susceptible to data changes over time. Predictive quality degrades when a concept drift occurs (nice and simple definition here).
Additionally, data integrity issues in any part of a complex system containing ML models may cause major performance mishaps. For example, a 3rd party adjusting a data source’s format, or an engineer introducing a bug in a pre-processing pipeline, may cause severe model underperformance and/or unexpected model behavior.
So how would data teams keep up? They need to monitor and continuously analyze ML model performance and take corrective actions. Such actions include generating or acquiring better training data, retraining models, or redirecting business applications to more suitable models.
In the spring of 2020, amid a global pandemic and an economic crisis, data teams are on high alert and expect data changes in the real world to “throw off” their models. However, having built-in, automated transparency into model behavior is even more critical in normal times, when nobody expects the issues to arise.
Production monitoring is a well established discipline in software. In fact, the practice is so entrenched in modern IT that some refer to monitoring as the most fundamental need of a production system. Naturally, there is a healthy industry of production monitoring solutions with well established cloud providers, such as the publicly traded Datadog, and New Relic. Yet, data teams find themselves searching for more tailored solutions, addressing the unique challenges of AI monitoring.
What are the unique requirements of monitoring AI systems?
From one perspective, AI systems are like Lego structures. The building blocks are gradually becoming standardized, but no two systems across two organizations are quite the same. Data teams design unique AI systems to fit the needs of their business. Therefore, AI monitoring has to be highly configurable by the user. The user has to be able to define/edit what is monitored, what constitutes relevant anomalous behavior, and when to get alerted on such behavior.
From another perspective, AI systems are like road networks. Problems could originate in one place and manifest in many others. Hence, it is insufficient for ML observability to just alert on anomalies. Automatic root-cause-analysis is integral to the model monitoring. Furthermore, predictive models should not be observed in a vacuum, but rather in the context of the full AI system. Perhaps quality degradation in one model is the result of a bug in a data processing stage that happens elsewhere in the system.
Finally, and as mentioned above, AI systems have hidden biases that manifest in model underperformance for subsegments of the data. When these biases explode into the surface, they can cause business catastrophes (customer rage, reputational hit, revenue loss, unexpected expenses of restaffing a team to investigate and fix). Therefore, data teams can’t settle for tracking average performance. For example, overall precision might be 95%, but are there segments of data for which precision is 70%? Are these segments of data important? Are they becoming more important over time?
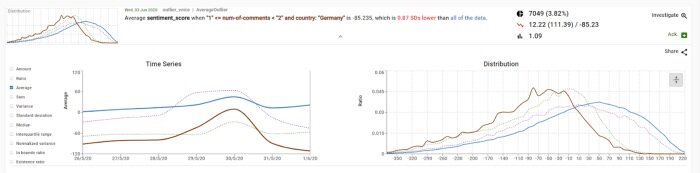 Figure 1: Model underperformance manifests visible over subsegments of the data
Figure 1: Model underperformance manifests visible over subsegments of the data
What is clear is that when AI systems are in “maintenance mode”, the risk of issues going unnoticed for some time is greater, and the importance of an expert monitoring platform becomes even greater.
What is our approach to ML observability?
These characteristics imply that AI performance requires more sophisticated statistical modeling.
First, the metrics. Most commonly, teams would track and review model precision and recall. However, what if there is no “ground truth”? No problem. There is still much to track in order to assess model behavior over time. For example, the features and outputs of models. We found that the highest performing AI teams track a whole spectrum of additional indicators, starting with confidence intervals, result counters (e.g., number of categories, depth and breadth), and other descriptive metrics of the result and feature spaces (e.g., density of clusters, correlations between classes).
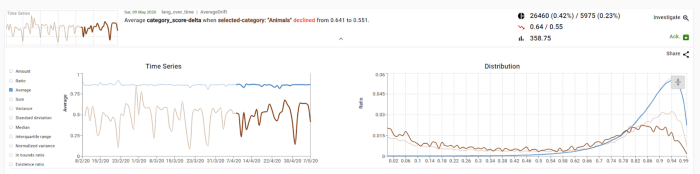
Second, the aggregation and analysis. We believe that best-in-class monitoring tool has to include looking into performance (for which the metrics are the proxy) in granular data segments. For example, to detect that a sentiment analysis model performs worse on shorter texts or in different parts of the country (with different slang and expressions).
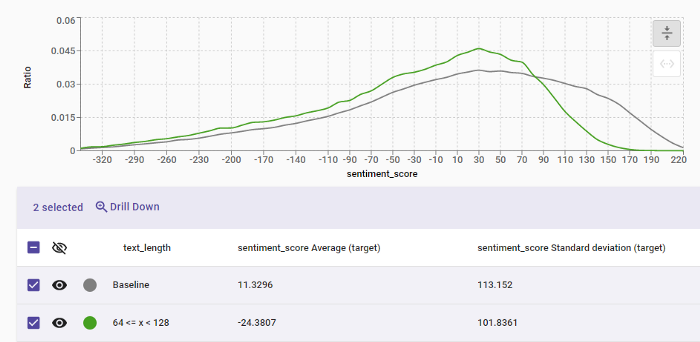
Figure 3: A sentiment model behaves differently on shorter texts
We believe that in order to implement AI monitoring successfully, much could be borrowed from Application Performance Monitoring (APM) — a well established solution space. In principle, we would like to make it as easy for data scientists to monitor AI systems, as it is for engineers to monitor infrastructure and applications.
Similar to APMs — we believe strongly that production monitoring should be standalone, tech stack agnostic, and put practitioners in control (to plan and execute their own monitoring) — the latter is a fairly recent evolution in APM.
Nevertheless, ML observability should also deviate from APM practices, primarily because AI monitoring requires more sophisticated statistical modeling. To enable that, AI monitoring requires more granular data collection and more sophisticated aggregation schemes.
So, we’ve built Mona to be a best-in-class AI monitoring platform that works with any development and deployment stack (and any model type or AI technique), is easy to integrate and configure, and yet gives data teams an “engineering arm” — to be in full control of the monitoring strategy and execution.
About Mona
The founders of Mona hail from Google Trends and McKinsey & Company and we have begun to build a team of brilliant and passionate big data engineers and data scientists to bring the vision to life.
About a year and a half ago, we ventured on a mission to empower data teams, to make predictive models transparent and trustworthy, and raise the collective confidence of business and technology leaders in their ability to make the most out of AI. We are grateful for the support of our early customers, our investors and advisors, and are excited to continue the journey to fulfill this mission.
Let’s go!
Special thanks to David Magerman and Ori Cohen for providing editorial feedback on this post.